Predict the Prices of Alt-coins Based on Twitter Data Literature Review
A cryptocurrency (or crypto currency) is a digital asset designed to work as a medium of exchange that uses cryptography to secure its transactions, control the creation of additional cryptocurrencies, and verify the secure transfer of assets [1]. Cryptocurrencies can be classified as types of digital or culling currencies, distinct from traditional currencies in that they are founded on the principle of decentralized control, compared to the central banking systems that typical currencies rely on [2]. The inception of cryptocurrencies dates back to 2008, when an unknown entity under the pseudonym Satoshi Nakamoto publicly released a paper titled Bitcoin: A Peer-to-Peer Electronic Cash System [3]. In January 2009, Nakamoto implemented the bitcoin software as open source lawmaking, releasing it to the public on SourceForge [4]. Nakamoto's contributions galvanized a wave of public attention, spurring others to create culling cryptocurrencies that relied on the aforementioned fundamental technology but were specialized in purpose [5].
This moving ridge of new cryptocurrencies has received much attending by the media and investors alike due to the assets' innovative features, potential capability as transactional tools, and tremendous toll fluctuations. In the by 2 years, the total marketplace capitalization of the entire cryptocurrency market has increased 11,600% from $7.4 billion dollars in Jan 2016 to over $800 billion dollars as of January 2018 [6]. This exponential growth is the result of both increased investor speculation and the introduction of various new cryptocurrencies, with current estimates of the total number of cryptocurrencies topping i, 400 dissimilar coins [7]. Thus, analyzing evolutionary dynamics of the cryptocurrency market place is a topic of electric current interest and tin can provide useful insight near the market share of cryptocurrencies [5, 8, 9]. Moreover, longitudinal datasets of Bitcoin transactions have been used to identify the socio-economical drivers in cryptocurrency adoption [ten].
The speculation behind these digital avails has increased to such magnitudes that fifty-fifty cryptocurrencies with no functionality have surpassed the marketplace value of established companies whose stocks are publicly traded in the equity markets. This rapid and exponential increase in cryptocurrency prices suggests that price fluctuations are driven primarily by retail investor speculation, and that this market exhibiting signs of a financial chimera [11]. In low-cal of this, a contempo study quantifies the inefficiency of the Bitcoin market by studying the long-range dependence of Bitcoin return and volatility from 2011 until 2017 [12]. Such dramatic volatility of the cryptocurrency marketplace may exist partly due to the inevitable fragility of decentralized systems based on blockchain technology [13]. Noteworthy, there has been increasing attending paid to improving our understanding of cryptocurrency marketplace behavior, for example, by ways of field experiments of peer influence (exerted by bots) on man trading decisions [14] and probabilistic modeling of purchase and sell orders [15].
Given that the alternative cryptocurrency market is dominated by retail investors, with few big institutional investors, sentiment on social media platforms and online forums may present a feasible medium to capture total investor sentiment [16]. More than recently, it has been shown that social media data such as Twitter can be used to track investor sentiment, and price changes in the Bitcoin market and other predominant cryptocurrencies [17–20]. In Garcia and Schweitzer [18], the authors demonstrate that Twitter sentiment, alongside economic signals of book, cost of commutation for USD, adoption of the Bitcoin technology, overall trading volume could be used to predict price fluctuations.
As a consequence, investors may have adopted a like strategy within the Bitcoin market, thereby weakening the correlation between Twitter sentiment and Bitcoin prices. Moreover, the daily trading volume of cryptocurrencies has increased such that weather condition are now suitable for high-frequency trading firms to exploit this correlation [21]. For proof of concept, we thus decided that using Twitter sentiment to analyze cost fluctuations of nascent alternative cryptocurrencies (commonly known equally "alt-coins") could provide valuable insight, and eventually lead to a viable arbitrage opportunity in other emerging alternative cryptocurrencies. Therefore, we aim to analyze and build a auto learning pricing model for this highly speculative market place through gauging investor sentiment via Twitter, a pervasive social network that has been strongly suggested to serve equally a powerful social bespeak for Bitcoin prices [18].
Materials and Methods
Nosotros began past researching different culling cryptocurrencies to ultimately make up one's mind which would be best suited within the confines of our analysis. Ultimately, we decided to choose ZClassic (ZCL), a private, decentralized, fast, open up-source community driven virtual currency, as the main target of our bookish focus given its unique technological dynamics and suitability of trading volume within the confines of our computational capacity. First off, the technological nature of the ZClassic cryptocurrency lends itself to a high level of predictability via tweet assay. Specifically, ZClassic is set to "hard fork" into Bitcoin Private on February 28th, 2018. A hardfork is a major change to blockchain protocol which makes previously invalid blocks or transactions valid [22].
As a result, the single cryptocurrency (ZClassic) preceding the difficult fork will be split into 2, ZClassic and Bitcoin Private [22]. Previous hardforks include Bitcoin Cash and Bitcoin Gold, and the history of each suggests that ZClassic'south price fluctuations volition be largely based off speculation regarding the future success and accessibility of Bitcoin Private. For example, any news release that is seen by investors every bit indicative of the possibility that Bitcoin Private will be traded on a major exchange or that the fork volition exist supported by a sure exchange will exert upward price pressure on the cryptocurrency's price. Every bit such, real-time tweet analysis serves equally a suitable means to gauge investor sentiment post-obit these news releases, and pinpoint spontaneous news releases themselves. Secondly, the relatively lower trading volume of ZCL compared to that of alternative cryptocurrencies suggests that it may be more than susceptible to sentiment-based price movement.
To collect the tweets, nosotros decided to base our program in RStudio, given its motley of costless Twitter-analysis packages and foundations within data analysis and statistical calculating. Specifically, we used the open up-sourced rtweet package [23], which accesses Twitter's Rest and stream APIs. Nosotros were able to utilise the rtweet parcel to retrieve, from each of the terminal 7 days, searching from midnight backwards, tweets that had the terms "ZClassic," "ZCL," and "BTCP." This drove procedure was repeated 3 times over the course of three and a half weeks to provide sufficient data for our analysis. We and then merged all data sets, and eliminated any duplicate tweets given that a single tweet could contain all three of these terms and therefore be accounted for thrice in the final data set up. In the end, we garnered a final data fix of 130, 000 unique tweets.
We then created an algorithm to classify each tweet as positive, negative, or neutral sentiment using tongue processing. The lexicon, primarily sourced from the Python package "Textblob," that assigns impactful words and phrases a polarity value (due east.1000., "top" and "not great" have values of 0.5 and −0.4, respectively), which we view as sentiment. Thus, each tweet is assigned a polarity value between −1 and 1 based on the combinations of keywords and phrases. If the unabridged tweet cord has a positive nonzero polarity value, our program scores the sentiment equally positive, or +i. If the entire tweet cord has a negative nonzero polarity value, our program scores the sentiment as negative, −i. If the polarity value is zip, so the tweet receives a sentiment value of 0.
Another of import aspect to annotation regarding the character of each tweet is the chained network event that each retweet creates. It is axiomatic that retweets can crusade a chain issue, thereby increasing the dispersion of the initial "tweet." Every bit such, information technology is possible that retweeted posts comprise new positive or negative information, or may exist viewed by the trading community as "insightful." For this reason, we decided to create a 2d sentiment index in which retweets would be more than heavily weighted than tweets themselves, using it as 1 of the features in grooming our model. We respectively assigned a weight of −2 or +2 to every negative and positive retweet because we assumed retweets signify more newsworthy events and have greater credibility than single tweets. Thus, we believe cryptocurrency investors will exist more likely to react to retweets than to unmarried tweets. Both the values of our weighted and unweighted sentiment indices were then calculated on an hourly footing by summing the weights of all coinciding tweets, which allowed us to directly compare this index to bachelor ZCL price data.
For model selection, we employed ten-fold cross validation on 589 information points to choose an optimal model framework amid linear regression, logistic regression, polynomial regression, exponential regression, tree model, and back up vector machine regression. A tree model called the Extreme Gradient Boosting Regression (also known as XGBoost [24]), exhibited the smallest loss, or inaccuracy, and was thus called to train the model on our data. The XGBoost model, likewise as other tree-based models, is peculiarly suited for applications on our data for the post-obit reasons:
i. Tree models are not sensitive to the arithmetic range of the data and features. Thus, we practise not need to normalize the data and possibly forestall loss due to normalization.
ii. Tree models are by far the well-nigh scalable machine learning model due to their construction processes—but adding more children nodes to the pre-existing tree nodes volition update the tree and permit our strategy to continue to accurately predict price as our collection of toll and tweet information increases into the future. It too makes the model adaptable for currencies with larger daily tweet volumes.
3. On the abstract level, the tree model is a rule-based learning method which, unlike a traditional regression learning method, has more than potential to unveil insightful relationships between features.
XGBoost is a tree ensemble model, which outputs a weighted sum of the predictions of multiple regression trees, past weighing mislabeled examples more heavily.
For completeness, we sketch the key ideas behind XGBoost as follows. Permit us ascertain
where is the prediction from our model for the i-th observation, ϕ(x i ) is our predicting function and each f representing a tree in our regression tree forest, . Our goal is to minimize the objective part , divers below:
where
The office represents a loss office, which in this instance is a mean-square part, and the Ω(f grand ) is a regularization, which penalizes each tree for having as well many leaves and to ensure smooth final learned weights. The definition of this regularization follows the in a higher place equation where due west is the coefficient at each node and is the number of leaves in the tree.
To minimize the to a higher place objective function, we employed a greedy Algorithm i to create our regression tree forest as originally implemented in Chen and Guestrin [24].

Algorithm 1: Exact greedy algorithm for split finding [24] used in our price prediction model.
One-third of the 589 information points is separated as the testing data, and the remainder is used as the training fix every bit nosotros built our Extreme Gradient Boosting Regression model. The model also tests unlike lead-lag on the range of [0, 1, 2, 3, iv, 5h] since we do not know how apace the public would react to the marketplace update or the social media sentiment. Based on the testing issue, we decided that there is a iii-h lag upshot betwixt social media information and toll effects.
Results
To begin, our tongue processing nomenclature algorithm showed meaning accuracy in identifying the sentiment of each tweet (see Table one). Examples of tweets that received positive, neutral, and negative sentiment values are shown in Table two.

Table 1. Validation analysis of algorithm sentiment prediction past transmission inspection.

Table 2. Examples of Tweets with positive, neutral and negative sentiment classifications in our dataset.
Upon reviewing our data set of tweets, ane major concern we had was the alluvion of computer-generated bot tweets, which often promote contests and giveaways. In do, retail investors frequently ignore these tweets, given their obvious usage as means of commercial promotions. These are often written using positive language; however, the vast majority of these were properly characterized as neutral. To further gauge the accuracy of our algorithm, we manually classified a sample of 100 random tweets, comparing them to our algorithm'southward classifications to measure simulated classification rates. Table one shows the general distinctions betwixt our algorithm's classifications and transmission classifications.
In all three cases we can see that the chance of the algorithm guessing the sentiment correctly is over 50%. The algorithm boasts a about 80% success rate in successfully classifying positive tweets, and correctly characterized 0% of positive tweets as negative in this sample. Notwithstanding, neutral and negative tweets were falsely characterized as positive at a rate of 34% and 25%, respectively. Negative tweets are successfully classified at a rate of 75%. Sarcasm remains very hard to detect (partially explaining the 25% false positive), but it typically appears in a minority of tweets.
Having set the sentiment classification algorithms in place, we decided to train our model using vi different features: Pure Positive Sentiment, Pure Negative Sentiment, Neutral Sentiment, An Unweighted Sentiment index, A Weighted Sentiment Index, and Hourly Trading Book. These 6 features proved to be varied enough to train the model effectively on a diverseness of dissimilar trading points and resulted in the best and about accurate overall correlation with the testing information (as shown in Table 3). The detailed co-plots of the different features vs. the toll curve over the written report period is shown in Figure one.
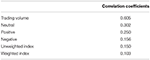
Table 3. 5-factor correlation coefficients between the chosen feature and the price data, respectively.
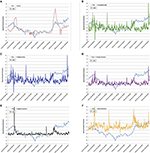
Figure 1. Shown are the price fluctuations vs. our called half-dozen features, respectively, over the time menses nether consideration: (A) Price vs. Volume, (B) Price vs. Unweighted Index, (C) Cost vs. Weighted Alphabetize, (D) Price vs. Pos. Sentiment, (East) Cost vs. Neg. Sentiment, and (F) Toll vs. Neutral Sentiment. These half dozen features proved to exist varied enough to railroad train the model effectively on a variety of different trading points and resulted in the best and virtually authentic overall correlation with the testing information, equally summarized in Table 3.
In testing our model, nosotros were able to produce price data that strongly reflected the actual fluctuations (encounter Figure two). In particular, it is pregnant that our model achieved a Pearson correlation of 0.806 when tested against the actual test data, yielding a statistical significance at the p < 0.0001 level. Every bit such, our model provides a viable method to predict price fluctuations, and also serves as a proof of concept that statistical analyses using Twitter sentiment tin can besides exist used to clarify price fluctuations in additional cryptocurrencies. It is also interesting to annotation that despite the similar directionality between the toll model and actual cost fluctuations, there appears to be a toll gap between the two of effectually $30 (encounter Effigy 2B). One possible explanation to this gap is the discrepancies betwixt the training and testing information (as summarized in Table 4). Commencement, it is important to note that the model was trained on data that primarily exhibited a negative trend (see Table 4). As such, it is possible that the model became more desensitized to positive stimuli, and more sensitive to negative stimuli. In the testing information, yet, the model was exposed to ~ 3% subtract in positive stimuli and ~ 0.five% increase in negative stimuli (Table iv). The number of average tweets per 60 minutes besides increased by ~ 15% (Tabular array 4). As such, it is possible that the model reacted to the modify in these factors past exhibiting a slightly lower price expectation than what the actual market reflected. Yet, the overall directionality and correlation within the model remained strong, suggesting that if the model were as well trained on data that exhibited positive trends, a more accurate set of predictions would have resulted.
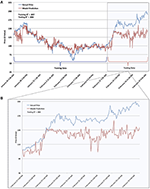
Figure 2. Comparison of model prediction and actual price data. (A) plots the fitted toll curve obtained from the preparation toll data and the predicted toll curve with respect to the testing data. (B) details the model prediction toll data equally compared to the testing existent toll data. By incorporating Twitter sentiment and trading volume, the Extreme Gradient Boosting Regression Tree Model provides a feasible means of predicting cost fluctuations inside the ZClassic cryptocurrency market. Moreover, it serves as a proof of concept that statistical analyses using Twitter sentiment can besides be used to analyze price fluctuations in other cryptocurrencies of interest.

Table four. Discrepancies of Twitter sentiments between testing and training information.
Discussion and Conclusions
In decision, our results suggest that by analyzing Twitter sentiment and trading book, an Extreme Slope Boosting Regression Tree Model serves as a viable means of predicting price fluctuations within the ZClassic cryptocurrency market. Every bit such, given the complete lack of inquiry within this academic sphere, our model serves as a proof of concept that social media platforms such as twitter tin be used to capture investor sentiment, and that this sentiment is an early on signal to future cost fluctuations in culling cryptocurrencies. Of detail involvement is seeing whether this arroyo produces similarly strong results when applied to other alternative cryptocurrencies such as ZCash and Bitcoin Private. Notwithstanding, this discovery sheds light to the possibility of arbitrage opportunities that utilise social media platform sentiment to predict time to come cryptocurrency prices.
Our pricing model could be further improved by factoring in other social media platforms or data, such as Google Search results, Facebook posts, and Reddit Posts. Contempo studies show that Wikipidia queries can also serve a potential point for quantifying the public interest in cryptocurrency [25]. These parallel platforms tin can be considered equally multiplex networks where the data/beliefs spreading process on one layer might impact like procedure on another layer [26–28]. Therefore, synthesizing data sources from multiple platforms where individuals may have "multiplex" interactions/influences of different sorts may atomic number 82 to better price predications. Moreover, the dictionary that we have used in our model could exist as well be aided past adding investment-specific terms that indicate positive and negative sentiment such every bit "bull" and "bear" respectively. As seen from our transmission vs. algorithm cross-assay, the algorithm's greatest weakness is in classifying tweets that should otherwise be characterized every bit "negative" as "positive." After careful review it is evident that such inaccurate characterizations are due to the algorithm'due south disability to observe sarcasm, a pervasive language schema in pop social media platforms. Every bit such, farther research to heighten our algorithm to detect sarcasm would increase the reliability of the sentiment analysis, and thereby potentially improve the accuracy of our prediction to retail driven price changes.
Lastly, it would exist interesting to further train and test our model over a longer time period. Given the confines of the date of our cryptocurrency's fork and our computational capacity, our study was restricted to a data prepare that covered a time frame of 3.5 weeks. Withal, our results suggest a necessity to devote further resources and investments that would enable us to implement study our pricing model under a longer time frame and with other cryptocurrencies.
Information Availability
All datasets generated for this study are included in the manuscript/supplementary files.
Writer Contributions
All authors performed analyses, discussed the results, and contributed to the text of the manuscript.
Conflict of Involvement Statement
The authors declare that the research was conducted in the absence of whatever commercial or fiscal relationships that could be construed equally a potential conflict of interest.
Acknowledgments
This work is supported by the William H. Neukom Institute for Computational Science at Dartmouth. FF gratefully acknowledges support from the G. Norman Albree Trust Fund, the Dartmouth Kinesthesia Startup Fund, Walter & Constance Burke Enquiry Initiation Laurels, and NIH Roybal Center Pilot Grant.
References
5. ElBahrawy A, Alessandretti 50, Kandler A, Pastor-Satorras R, Baronchelli A. Evolutionary dynamics of the cryptocurrency market. R Soc Open up Sci. (2017) 4:170623. doi: ten.1098/rsos.170623
PubMed Abstract | CrossRef Full Text | Google Scholar
9. Alessandretti Fifty, ElBahrawy A, Aiello LM, Baronchelli A. Anticipating cryptocurrency prices using machine learning. Complexity. (2018) 2018:8983590. doi: 10.1155/2018/8983590
CrossRef Full Text | Google Scholar
10. Parino F, Gauvin L, Beiro MG. Analysis of the Bitcoin blockchain: socio-economic factors backside the adoption. arXiv:1804.07657. (2018). doi: ten.1140/epjds/s13688-018-0170-8
CrossRef Full Text | Google Scholar
12. Bariviera AF. The inefficiency of Bitcoin revisited: a dynamic approach. Econ Lett. (2017) 161:1–4. doi: x.1016/j.econlet.2017.09.013
CrossRef Total Text | Google Scholar
13. De Domenico M, Baronchelli A. The fragility of decentralised trustless socio-technical systems. EPJ Data Sci. (2019) 8:two. doi: 10.1140/epjds/s13688-018-0180-six
CrossRef Full Text | Google Scholar
14. Krafft PM, Della Penna N, Pentland A. An experimental written report of cryptocurrency market dynamics. arXiv:1801.05831. (2018). doi: 10.1145/3173574.3174179
CrossRef Full Text | Google Scholar
15. Guo T, Antulov-Fantulin N. Predicting short-term Bitcoin price fluctuations from buy and sell orders. arXiv:1802.04065. (2018).
Google Scholar
16. Leinz K. Who is ownership bitcoin? This charts reveals the answer money. Time. (2018, January 24). Available online at: time.com/money/5116904/who-is-buying-bitcoin/ (accessed April 30, 2018).
Google Scholar
17. Meucci A. 'P' Versus 'Q': differences and commonalities between the 2 areas of quantitative finance. GARP Take a chance Professional, 47–50. (2011, Feb). Bachelor online at: http://ssrn.com/abstract=1717163 (accessed January 22, 2011).
Google Scholar
19. Kim YB, Kim JG, Kim W, Im JH, Kim Th, Kang SJ, et al. Predicting fluctuations in cryptocurrency transactions based on user comments and replies. PLoS One. (2016) 11:e0161197. doi: 10.1371/periodical.pone.0161197
PubMed Abstract | CrossRef Total Text | Google Scholar
20. Phillips RC, Gorse D. Predicting cryptocurrency price bubbles using social media data and epidemic modelling. In: Computational Intelligence (SSCI), 2017 IEEE Symposium Series on 2017 Nov 27. IEEE (2017). p. 1–vii.
Google Scholar
21. Williams-Grut O. The cryptocurrency market is now doing the same daily book equally the New York Stock Exchange. Business Insider. (2017, December 20).
Google Scholar
24. Chen T, Guestrin C. XGboost: a scalable tree boosting system. In: Proceedings of the 22nd ACM SIG KDD International briefing on Knowledge Discovery and Data Mining. San Francisco, CA: ACM (2016). p. 785–94.
Google Scholar
25. ElBahrawy A, Alessandretti Fifty, Baronchelli A. Wikipedia and digital currencies: interplay between commonage attending and market performance. arXiv:1902.04517. (2019).
Google Scholar
26. Szolnoki A, Perc G. Information sharing promotes prosocial behaviour. N J Phys. (2013) fifteen:053010. doi: 10.1088/1367-2630/15/v/053010
CrossRef Full Text | Google Scholar
28. Wang Z, Wang L, Szolnoki A, Perc M. Evolutionary games on multilayer networks: a colloquium. Eur Phys J B. (2015) 88:124. doi: ten.1140/epjb/e2015-60270-7
CrossRef Total Text | Google Scholar
Source: https://www.frontiersin.org/articles/10.3389/fphy.2019.00098/full
{kind=link}
Post a Comment for "Predict the Prices of Alt-coins Based on Twitter Data Literature Review"